Le Pipeline

1.Définition
Notre projet visait à développer une solution à la fois flexible et efficace pour extraire l’information à partir d’une variété de formats de documents. On est concentré sur l’utilisation de l’OCR (Optical Character Recognition) et des modèles à grand langage (LLMs) comme ChatGPT en utilisant les capacités contextuelles avancées des LLM. L’innovation de cette méthode réside dans son adaptabilité, capable de traiter de nombreux types de documents sans formation approfondie ni règles spécifiques pour chaque format. Notre objectif était de démontrer une stratégie efficace pour l’extraction de données qui pourrait être un point de référence pour les défis similaires rencontrés dans divers contextes d’affaires.
2.Déférentes possibilités
Dans cette partie on explore les déférentes possibilités pour extraction et l’analyse de l’information. chaque solution avec ces avantages et inconvénients.
2.1.GPT-4 Vision (GPT-V) by OpenAI
GPT-V se distingue par sa capacité à analyser des images et à fournir des informations détaillées basées sur les requêtes des utilisateurs. Ce modèle permet aux utilisateurs de télécharger une image et de poser des questions spécifiques sur son contenu, auxquelles GPT-V répond avec des informations précises et pertinentes. Dans le cadre de l’extraction de données à partir d’images, GPT-V offre une solution hautement intuitive et efficace. Le processus est remarquablement simple : vous téléchargez une image sur le modèle, et GPT-V traite cette image pour renvoyer les informations requises dans un format JSON structuré. Ces données peuvent ensuite être facilement stockées et récupérées pour une utilisation ultérieure.
Avantages de l’utilisation de GPT-V :
Simplicité et efficacité : Le processus de téléchargement d’une image et de réception de données au format JSON est simple, ce qui minimise la complexité généralement associée à l’extraction de données.
Haute efficacité : GPT-V utilise les capacités sophistiquées du modèle GPT-4, assurant une extraction de données précise et fiable à partir d’images.
Inconvénients de l’utilisation de GPT-V :
Considérations de coût : L’utilisation de GPT-V peut être coûteuse, en particulier lors du traitement d’images à haute résolution, ce qui peut être un facteur important pour les projets avec des contraintes budgétaires.
Préoccupations relatives à l’autonomie des données : Comme GPT-V est un service tiers, il existe des problèmes inhérents à la confidentialité et au contrôle des données. Cette dépendance envers un fournisseur externe peut poser des défis pour les projets où la sécurité et l’autonomie des données sont primordiales.
Latence et limites de débit de l’API : Il peut y avoir des retards importants dans la réception des informations de l’API, et des limites de débit peuvent être imposées au compte, affectant l’évolutivité et la réactivité du système.
Installation:
!pip install requests openai
import base64
import requests
from openai import OpenAI
# OpenAI API Key
api_key = "Insert-Your-OpenAi-API-Key-Here"
client = OpenAI(api_key = api_key)
Pour commencer à utiliser GPT-V, vous devez d’abord créer un compte sur le site Web OpenAI. Dans ce cas, vous devez d’abord vous connecter à lOpenAI, puis générer des API keys pour vos API_keys. Il est important de noter que l’accès GPT-V nécessite au moins un paiement effectué sur votre compte. Une fois ces conditions préalables remplies, OpenAI vous donnera accès à GPT-V.
Maintenant, écrivons une fonction d’aide.
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
Avant de faire une requête API, l’image locale doit être convertie dans un format compatible avec GPT-V. C’est là que la fonction encode_image() entre en jeu. Il prend une image stockée localement et la convertit en sa version encodée base64, prête pour la requête API.
Ensuite, nous écrivons le code qui nous aidera à envoyer la demande API.
def question_image(url,query):
if url.startswith("http://")or url.startswith("https://"):
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": f"{query}"},
{
"type": "image_url",
"image_url": url,
},
],
}
],
max_tokens=1000,
)
return response.choices[0].message.content
else:
base64_image = encode_image(url)
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": f"{query}?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
},
}
]
}
],
"max_tokens": 1000
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
temp=response.json()
return temp['choices'][0]['message']['content']
La fonction question_image() peut sembler complexe au départ, mais elle consiste principalement en un code standard. Faisons une explaication pour mieux comprendre :
url : Cela peut être une URL vers une image en ligne ou un chemin de fichier local.
query : La question ou l’invite spécifique que vous souhaitez poser sur l’image.
Gestion des URL en ligne : Si l’URL est une URL en ligne, la fonction exécute le code dans l’instruction “if”, et si il s’agit d’une image locale elle exécute le code de “else” .
Note
La configuration du paramètre max_tokens contrôle la longueur de la réponse générée par le modèle.Une grand valeur peut augmenter le temps de traitement et l’utilisation des ressources. L’ajustement de la valeur max_tokens dépend de votre cas d’utilisation spécifique et de la longueur désirée des réponses que vous attendez du modèle. Vous pouvez expérimenter avec différentes valeurs pour trouver la longueur optimale pour votre application.
Il faut specifier votre api_key obtenue dans votre compte OpenAI.
format_response La modification de cette valeur dans l’appel API peut guider le modèle pour répondre strictement au format JSON bien structuré.
Pour en savoir plus sur format_response et d’autres paramètres, cliquez ici.
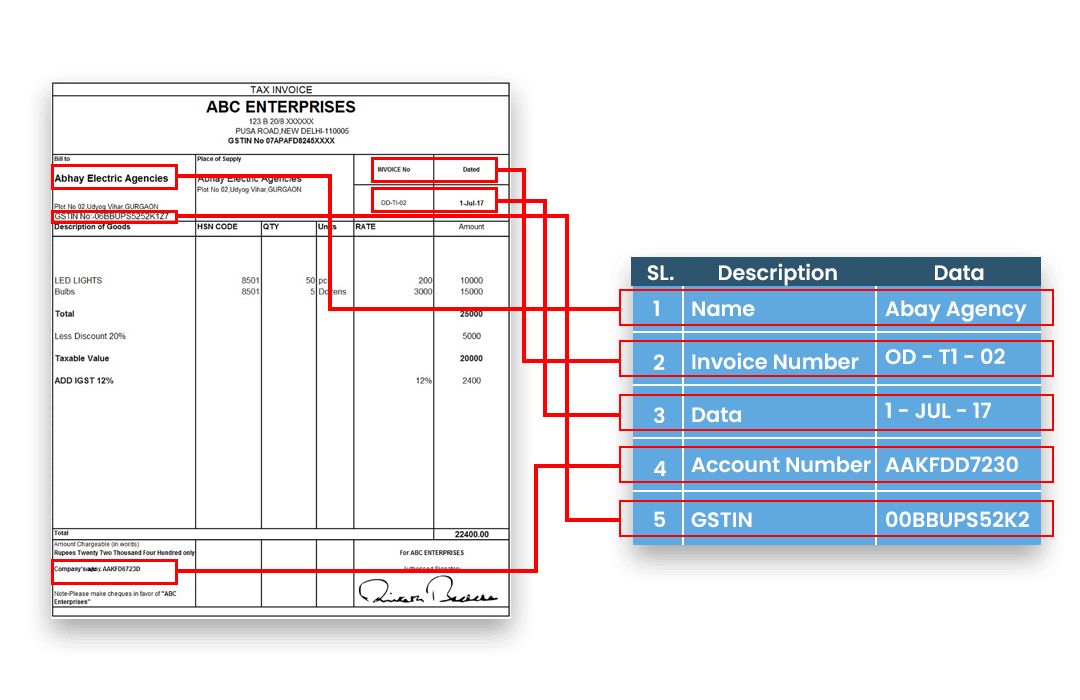
Example: Maintenant, tout ce qui est nécessaire est de passer une image avec une requête pour effectuer l’extraction de texte. On utilise une carte d’embarquement de Singapore Airlines.

query="Extract the airline_name,passenger_name,flight_num,departure_city,destination_city and date_of_departure from this boarding pass in a JSON format"
image_url="singapore.jpg"
boarding_pass_json=question_image(image_url,query)
print(boarding_pass_json)
json
{
"airline_name": "Singapore Airlines",
"passenger_name": "Heng Kok Hong Mr",
"flight_num": "SQ 231",
"departure_city": "SIN (Singapore)",
"destination_city": "SYD (Sydney)",
"date_of_departure": "19JAN18"
}
2.2.Azure Cognitive Services and GPT 3.5 Turbo by OpenAI
Pour cette approche, vous pouvez utiliser Azure Cognitive Services (ACS) comme outil OCR et GPT 3.5 Turbo pour la structuration des données. ACS excelle dans l’extraction de tout le texte présent dans une image, en le convertissant d’un format visuel en un format textuel lisible par machine et non structuré. Ensuite, la fonction de formatage JSON de GPT 3.5 Turbo est utilisée pour restructurer ce texte brut. L’intégration des puissantes capacités OCR d’ACS avec la capacité de structuration de données avancée de GPT 3.5 Turbo permet une extraction d’informations très précise. Le résultat n’est pas seulement une simple transcription du texte de l’image, mais une représentation JSON bien organisée et structurée des informations contenues à l’origine dans l’image.
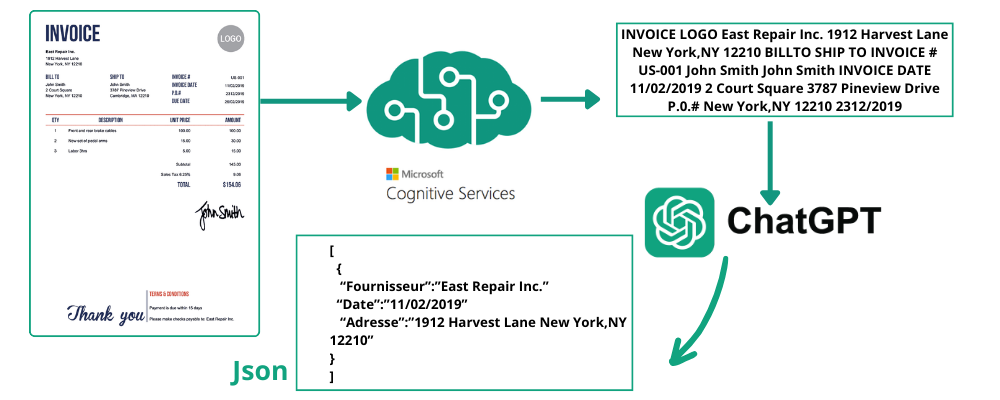
Avantages de l’utilisation de ACS et GPT 3.5 Turbo:
OCR précision : ACS fournit une extraction de texte de haute qualité.
Structuration avancée des données : GPT 3.5 Turbo transforme efficacement le texte non structuré en JSON structuré.
Inconvénients de l’utilisation de ACS et GPT 3.5 Turbo:
Coût : Bien qu’elle ne soit pas aussi coûteuse que la GPT-V,cette approche implique toujours des dépenses pour les services externes et la dépendance envers un serveur externe.
Confidentialité des données : Problèmes potentiels avec l’autonomie des données en raison de la dépendance au traitement externe.
Latence et limites de débit de l’API : Similaire à GPT-V, cette méthode est confrontée à des problèmes de délais et de limites de débit potentielles sur l’utilisation de l’API, ce qui affecte les capacités de traitement en temps réel
2.3.Local OCR and LLM
Pour cette approuche on va utiliser un outil OCR local comme PaddleOCR,EasyOCR… pour l’extraction du texte suivie avec un LLM pour Token Classification afi d’extraire les informations pertinentes.
Avantages de l’utilisation local OCR and LLM:
Économique : Aucun coût supplémentaire pour les services externes.
Sécurité des données : La confidentialité des données est renforcée car le traitement est effectué au sein de votre écosystème.
Indépendance vis-à-vis des API : Le manque de dépendance vis-à-vis des API externes élimine les préoccupations concernant les limites de débit et la latence,la vitesse ne dépendant que du matériel de l’utilisateur.
Inconvénients de l’utilisation de local OCR and LLM:
Exigences d’infrastructure : Nécessite des ressources de calcul importantes pour la mise à l’échelle.
Vitesse d’inférence : La vitesse de traitement dépend du matériel disponible, ce qui pourrait être une limitation pour les utilisateurs de systèmes moins puissants.