NER modèles
1.Qu’est-ce que la reconnaissance d’entité ?
La reconnaissance d’entité (Name entity recognition) fait partie du traitement du langage naturel. L’objectif premier de NER est de traiter données structurées et non structurées et classer ces entités dans des catégories prédéfinies. Certaines catégories courantes incluent le nom, le lieu, l’entreprise, l’heure, les valeurs monétaires, les événements, etc.
En quelques mots, NER s’occupe de :
Reconnaissance/détection d’entités
Identification d’un mot ou d’une série de mots dans un document.
Classification des entités
Classement de chaque entité détectée dans des catégories prédéfinies.
Mais comment le NER est-il lié à la NLP ?
Le traitement du langage naturel aide à développer des machines intelligentes capables d’extraire le sens de la parole et du texte. L’apprentissage automatique aide ces systèmes intelligents à continuer à apprendre en s’entraînant sur de grandes quantités de langage naturel ensembles de données.
Généralement, la NLP se compose de trois grandes catégories :
Comprendre la structure et les règles de la langue,Syntaxe.
Déduire le sens des mots, du texte et de la parole et identifier leurs relations sémantiques.
NER aide dans la partie sémantique de la NLP, extrayant le sens des mots, les identifiant et les localisant en fonction de leurs relations.
2.Exemples de reconnaissance d’entités nommées
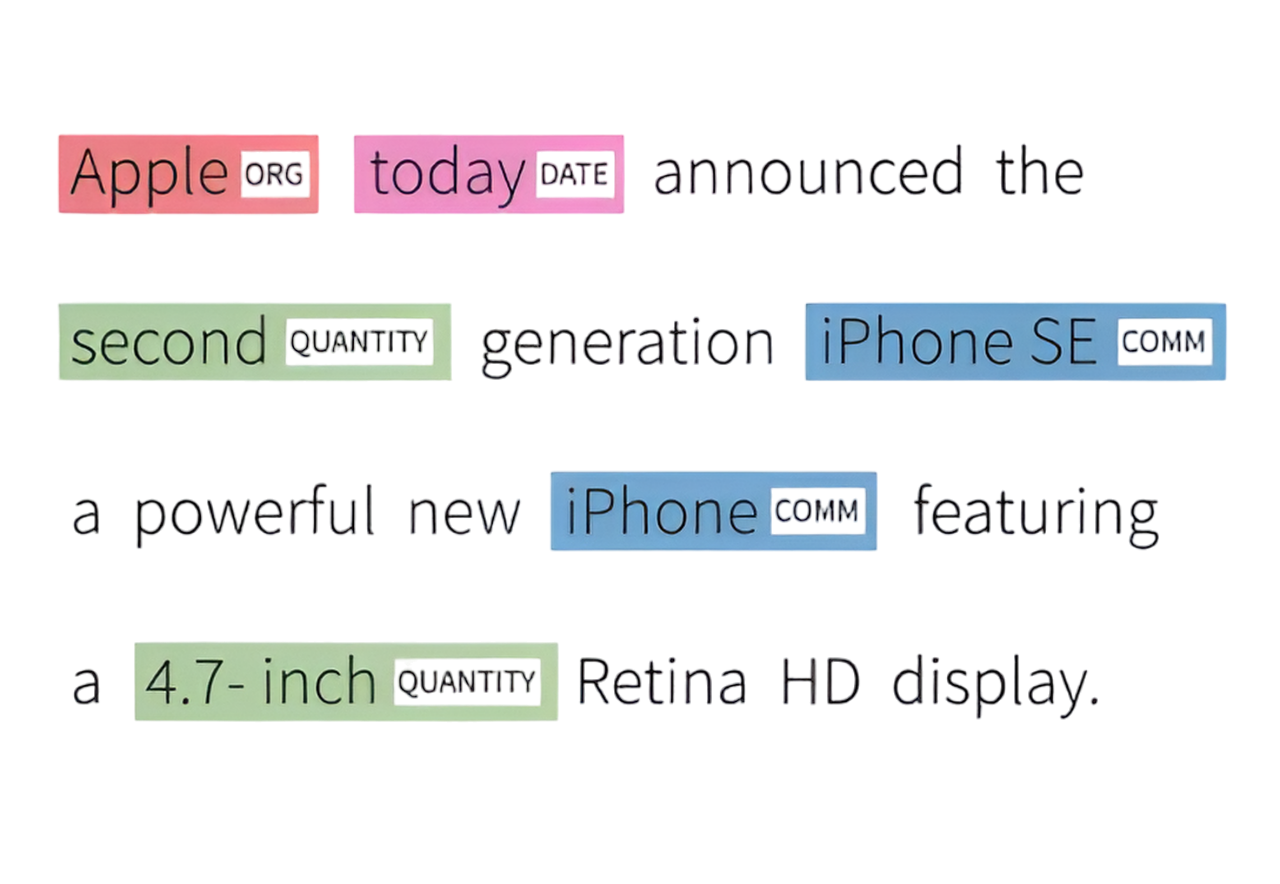
Certains des exemples courants d’un catégorisation d’entité sont:
Apple : est étiqueté ORG (Organisation) et surligné en rouge.
today : est étiqueté DATE et surligné en rose.
Second : est étiqueté QUANTITÉ et surligné en vert.
iPhone SE : est étiqueté COMM (Produit commercial) et surligné en bleu.
4.7-inch : est étiqueté QUANTITÉ et surligné en vert.
Ambiguïté dans la reconnaissance d’entité nommée
La catégorie à laquelle appartient un terme est intuitivement assez claire pour les êtres humains. Cependant, ce n’est pas le cas des ordinateurs,ils rencontrent des problèmes de classification. Par example: Manchester City (Organisation) a remporté le trophée de la Premier League alors que dans la phrase suivante, l’organisation est utilisée différemment. Manchester City (Localisation) était une centrale électrique textile et industrielle. Votre modèle NER a besoin données d’entraînement mener avec précision extraction d’entité et classement. Si vous entraînez votre modèle sur l’anglais shakespearien, il va sans dire qu’il ne pourra pas déchiffrer Instagram.
3.Différentes approches NER
L’objectif premier d’un Modèle NER consiste à étiqueter des entités dans des documents texte et à les catégoriser. Les trois approches suivantes sont généralement utilisées à cette fin. Cependant, vous pouvez également choisir de combiner une ou plusieurs méthodes. Les différentes approches pour créer des systèmes NER sont :
Systèmes basés sur un dictionnaire
Le système basé sur un dictionnaire est peut-être l’approche NER la plus simple et la plus fondamentale. Il utilisera un dictionnaire avec de nombreux mots, des synonymes et une collection de vocabulaire. Le système vérifiera si une entité particulière présente dans le texte est également disponible dans le vocabulaire. En utilisant un algorithme de mise en correspondance de chaînes, une vérification croisée des entités est effectuée. Un inconvénient de l’utilisation de cette approche est qu’il est nécessaire de mettre à jour constamment l’ensemble de données de vocabulaire pour le fonctionnement efficace du modèle NER.
Systèmes basés sur des règles
Dans cette approche, les informations sont extraites sur la base d’un ensemble de règles prédéfinies. Il existe deux principaux ensembles de règles utilisées,
Règles basées sur des modèles : Comme son nom l’indique, une règle basée sur un modèle suit un modèle morphologique ou une chaîne de mots utilisée dans le document.
Règles basées sur le contexte : Les règles contextuelles dépendent de la signification ou du contexte du mot dans le document.
Systèmes basés sur l’apprentissage automatique
Dans les systèmes basés sur l’apprentissage automatique, la modélisation statistique est utilisée pour détecter les entités. Une représentation basée sur les caractéristiques du document texte est utilisée dans cette approche. Vous pouvez surmonter plusieurs inconvénients des deux premières approches puisque le modèle peut reconnaître types d’entités malgré de légères variations dans leur orthographe.
L’apprentissage en profondeur
Les méthodes d’apprentissage en profondeur pour NER exploitent la puissance des réseaux de neurones tels que les RNN et les transformateurs pour comprendre les dépendances de texte à long terme. Le principal avantage de l’utilisation de ces méthodes est qu’elles sont bien adaptées aux tâches NER à grande échelle avec des données d’entraînement abondantes. De plus, ils peuvent apprendre des modèles et des fonctionnalités complexes à partir des données elles-mêmes, éliminant ainsi le besoin de formation manuelle. Mais il y a un piège. Ces méthodes nécessitent une grande puissance de calcul pour la formation et le déploiement.
Méthodes hybrides
Ces méthodes combinent des approches telles que l’apprentissage basé sur des règles, statistique et automatique pour extraire des entités nommées. L’objectif est de combiner les atouts de chaque méthode tout en minimisant leurs faiblesses. L’avantage de l’utilisation de méthodes hybrides est la flexibilité que vous obtenez en fusionnant plusieurs techniques grâce auxquelles vous pouvez extraire des entités de diverses sources de données. Cependant, il est possible que ces méthodes finissent par devenir beaucoup plus complexes que les méthodes à approche unique, car lorsque vous fusionnez plusieurs approches, le flux de travail peut devenir confus.
NER Models Benchmarking
Nous avons fait une comparaison entre différents grands modèles de langage, nous avons cité différents modèles en utilisant Hugging Face et LM Studio.
Note
il faut préparer les données pour chaque modèle pour le Finetuning, ça prend beaucoup de temps et chaque modèle se caractérise par un type des données d’entrée.
C’est pour cela nous avons utiliser la partie Spaces sur Hugging face.
1.Magorshunov/layoutlm-invoices
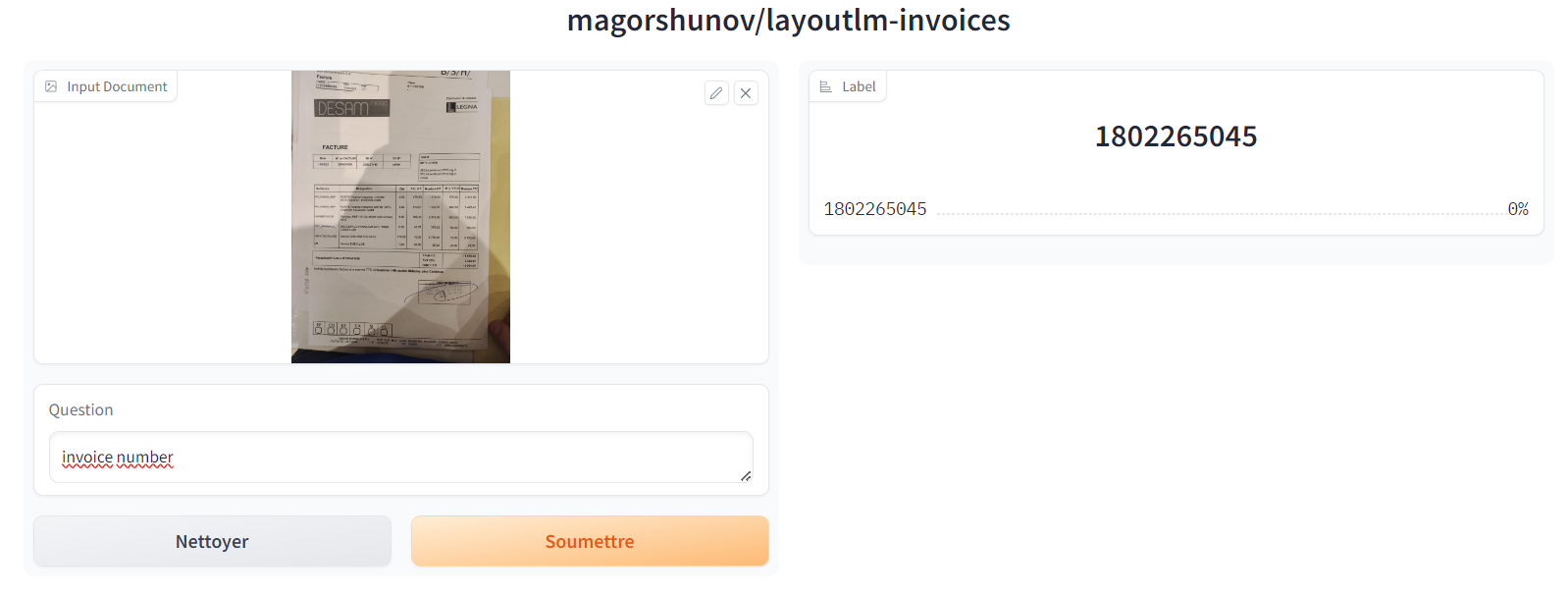
Note
Vous pouvez essayer ce modèle en cliquant ici.
2.Faisalraza/layoutlm-invoices
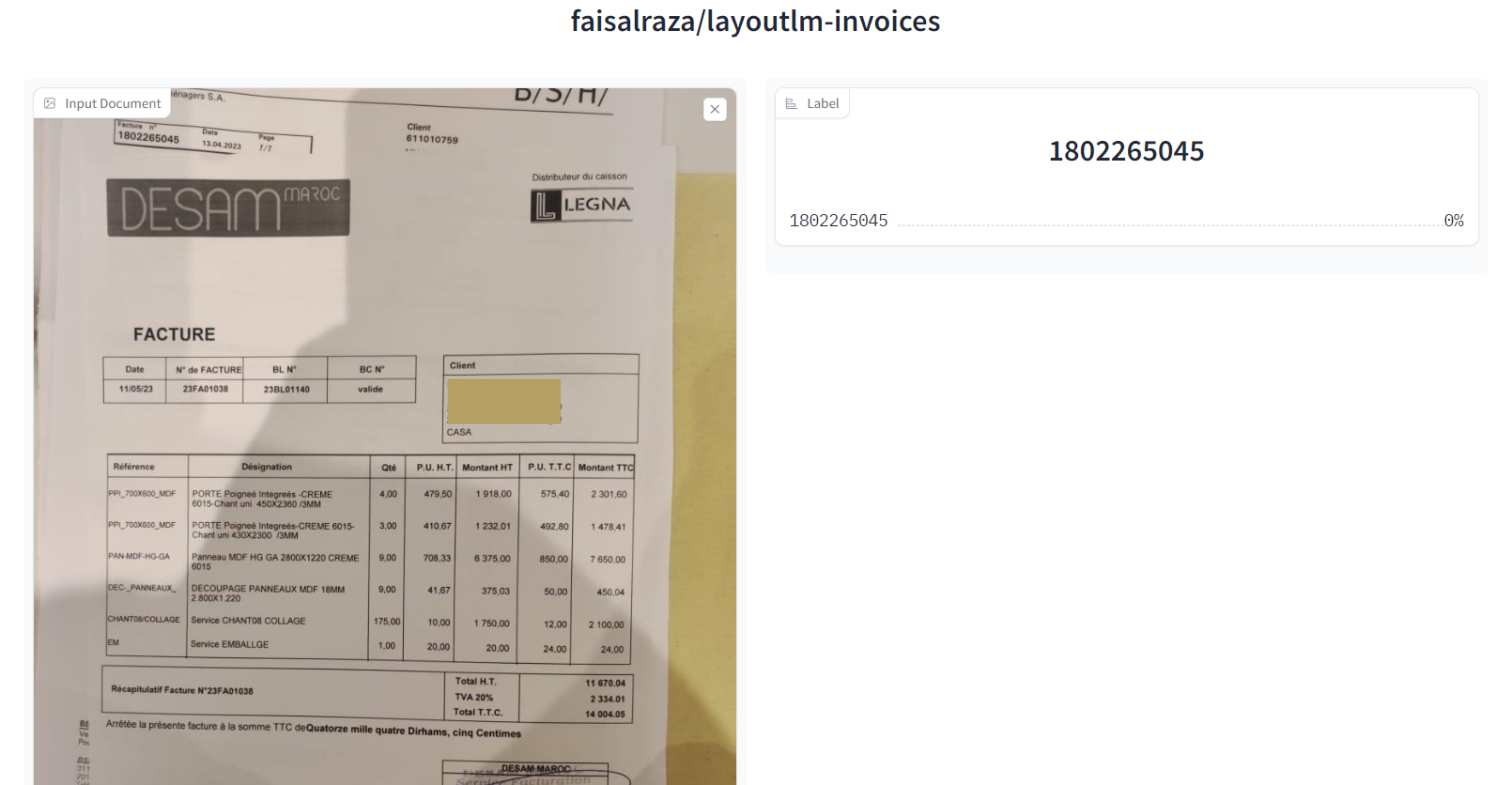
Note
Vous pouvez essayer ce modèle en cliquant ici.
3.Impira/layoutlm-invoices

Note
Vous pouvez essayer ce modèle en cliquant ici.
4.Invoice header extraction with Donut
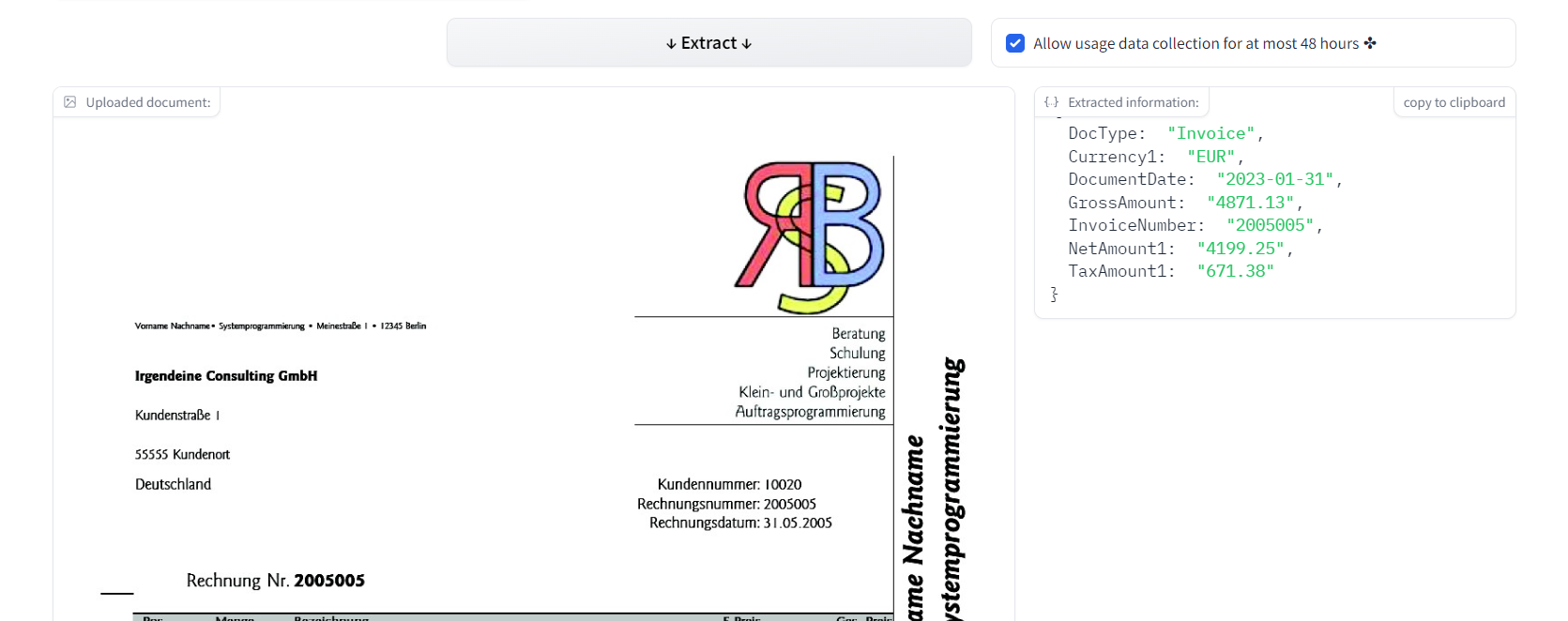
Note
Vous pouvez essayer ce modèle en cliquant ici.
5.Gemini application
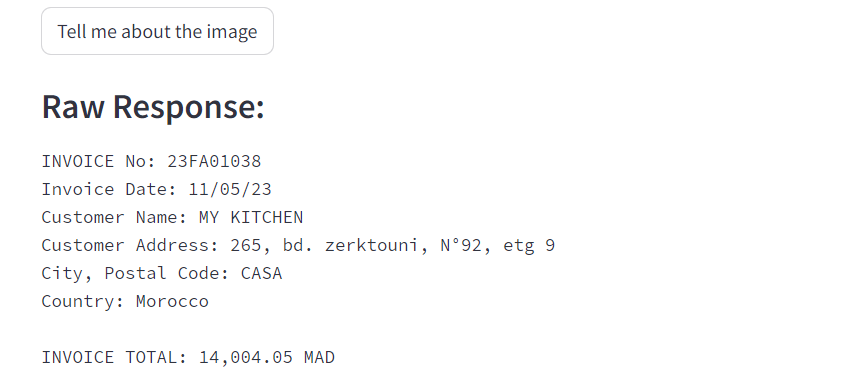
Note
Vous pouvez essayer ce modèle en cliquant ici.
6.Generative AI / invoice reader
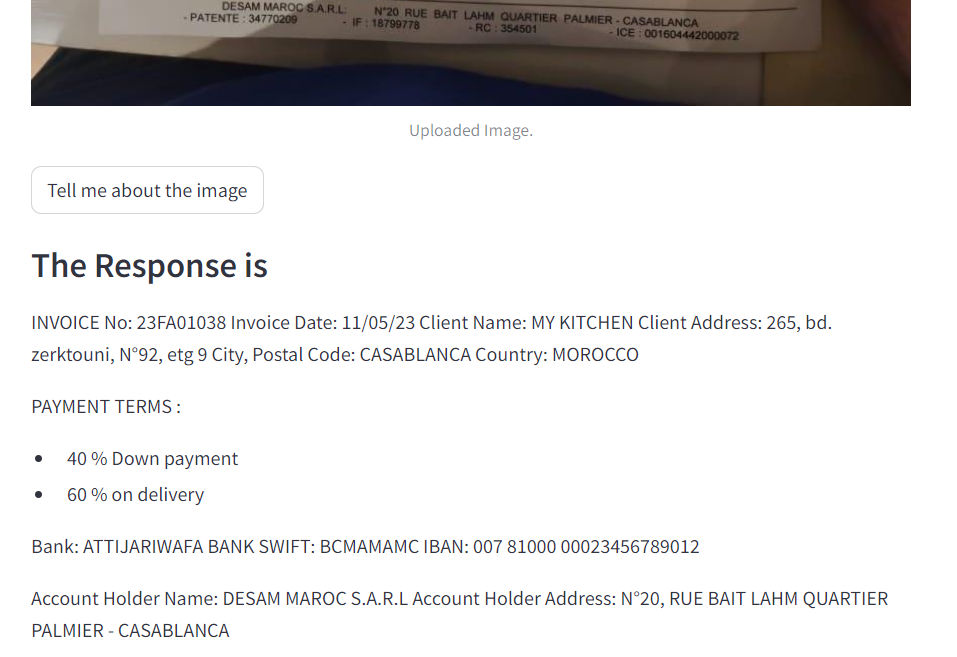
Note
Vous pouvez essayer ce modèle en cliquant ici.
7.Invoice Information Extraction using LayoutLMv3 model
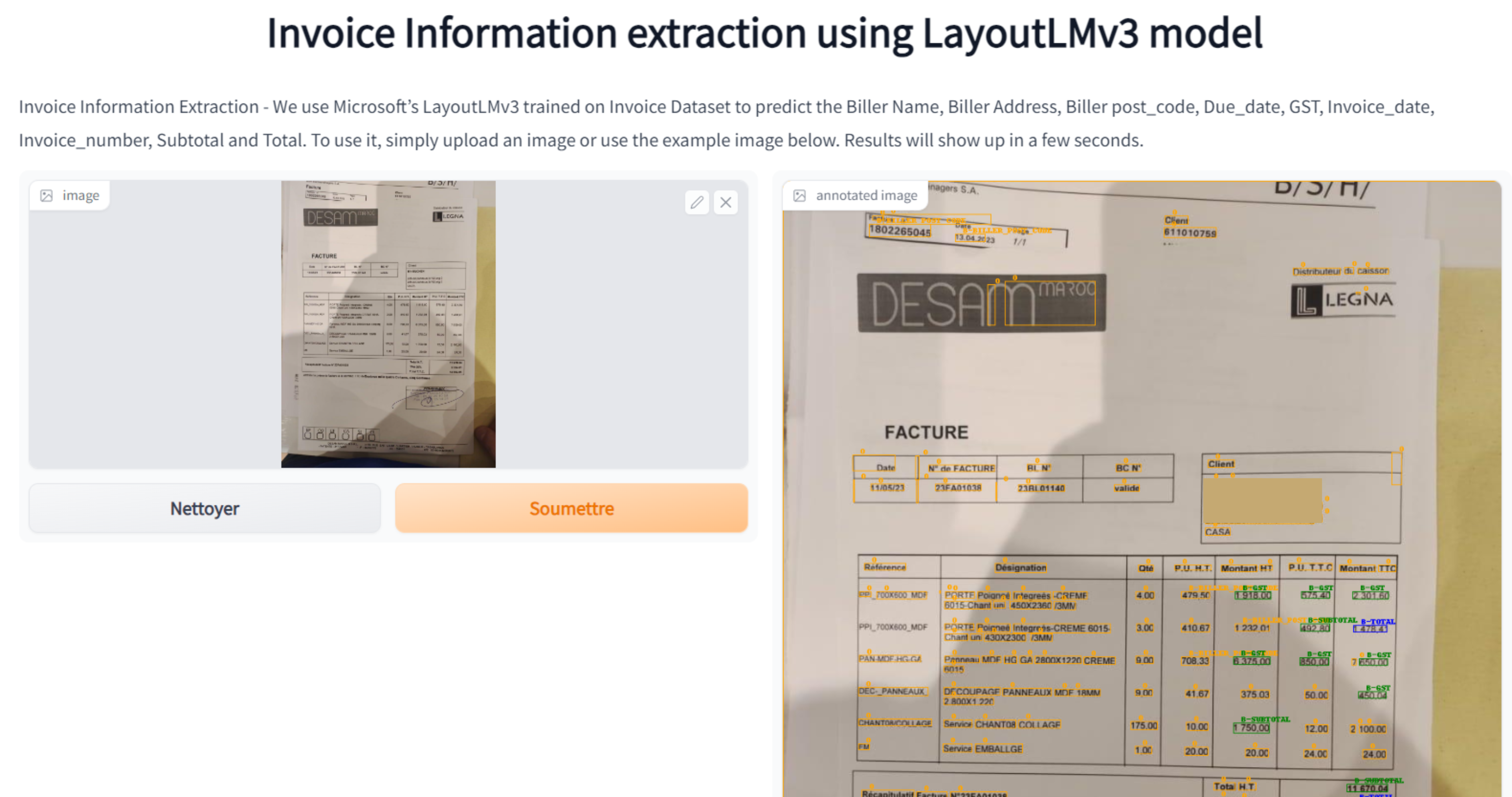
Note
Vous pouvez essayer ce modèle en cliquant ici.
Nous avons réalisé une analyse comparative approfondie de plusieurs modèles de langage de grande envergure (LLM) pour l’extraction de texte à partir de documents. Notre évaluation s’est principalement concentrée sur deux critères essentiels : le temps d’inférence requis par chaque modèle et le poids, ou la taille, de ces modèles. En examinant attentivement ces aspects, nous avons pu classer ces modèles en fonction de leur performance et de leur efficacité dans le contexte de l’extraction de texte. Cette classification nous a fourni des insights précieux sur les forces et les faiblesses de chaque modèle, nous permettant ainsi de prendre des décisions éclairées quant à leur utilisation dans divers scénarios d’application.
Voici une video qui vous aidera à trouver et essayer les NER modèles