Training
7.1 Création de dataSet sur HuggingFace
pour la suite on va prendre comme exemple les deux images suivantes:

Aprés labelisation de vos images et obtenir le fichier json,de cette forme.
Indication
Le json est de forme d’une liste contenait deux dictionnaires, chacun pour une image on a pris que deux images à titre d’exemple, mais vous allez utiliser plusieurs.
La suite de code est elaboré sur Google Colab.
7.1.1 Preparation de fichier json
Le fichier obtenu jusqu’à maintenant n’est pas encore compatible avec la forme qui accepte la famille des modèles LayoutLM parmi ses non compatibilités :
bbox (les coordonnées des rectangles de chaque labelisation [xmin,ymin,xmax,ymax] ) ne sont pas normalisés entre [100,1000].
bbox sont des float , on doit avoir des entières.
Dans la nouvelle forme, on a une liste contient les informations des images, chacune est représentée par un dictionnaire dont les clés sont [“id”, “image”, “bboxes”, “ner_tags”, “tokens”]
# Import some Libraries
import json # v2.0.9
import os
from PIL import Image # v9.4.0
import io
Attention
Prends garde aux versions des bibliothèques mentionnées dans les commentaires ci-dessus.
Pour le training, on travaille avec Python 3.10.12.
def Get_Image(Image_name):
filename = Image_name
image_path = os.path.join("PATH_YOUR_TRAINING_IMAGES",filename)
print(image_path)
with open(image_path, 'rb') as file:
binary_image_data = file.read()
image = Image.open(io.BytesIO(binary_image_data))
return image
Cette fonction renvoie une image ce format Pillow, prenant en paramètre le nom de l’image Image_name.
PATH_YOUR_TRAINING_IMAGES est le chemin de votre dossier contenant les images de Training les même que vous allez labelliser sur Labet-Studio. par exemple /content/drive/MyDrive/Exemple/Data.
def Get_Annoutaions(Annoutaion):
bboxes = []
ner_tags = []
tokens = []
Number_annotaions = len(Annoutaion)
for j in range(Number_annotaions):
box = Annoutaion[j]["box"]
text = Annoutaion[j]["text"]
tag = Annoutaion[j]["label"]
#Transform box data :
box = [int(x * 10) for x in box]
# Append
bboxes.append(box)
tokens.append(text)
ner_tags.append(tag)
return bboxes,tokens,ner_tags
Get_Annoutaions renvoie 3 listes : bboxes, tokens et ner_tags, chacune contenant les informations des annotations de l’image. il corrige aussi le probleme de la bbox qui n’est pas normalisée entre [100,1000] en multipiant par 10.
def Prepare_Data(Json_path):
dataSet = []
# Read the JSON file
with open(Json_path, 'r') as file:
data = json.load(file)
n = len(data) # n : Number_Images
for i in range(n):
###########################################
image = Get_Image(data[i]["file_name"])
########################################
bboxes,tokens,ner_tags=Get_Annoutaions(data[i]["annotations"])
#print(ner_tags)
############################################
document_dict = {
'id': i,
'image': image,
'bboxes': bboxes,
'ner_tags': ner_tags,
'tokens': tokens
}
dataSet.append(document_dict)
return dataSet
Prepare_Data renvoie une liste de dictionnaires dont les clés sont [“id”, “image”, “bboxes”, “ner_tags”, “tokens”],prenant en paramètre le chemin de fichier json Json_path.
Json_path = "PATH_YOUR_TRAINING_JSON_FILE"
dataSet = Prepare_Data(Json_path)
print("Number of Images : ",len(dataSet))
Cette cellule renvoie un dictionnaire dataSet contient l’ensemble des informations de chaque image.
PATH_YOUR_TRAINING_JSON_FILE est le chemin de votre fichier json, par exemple /content/drive/MyDrive/Exemple/Exemple_Training.json.
7.1.2 Compte HuggingFace
Vous connaissez pas HuggingFace ?,c’est qui est une grande plateforme d’IA avec une large communauté, contient les modèles préétablis, des datasets, des espaces…, on vous laisse la main pour découvrir plus.
On besoin d’abord de créer un compte sur HuggingFace, si vous l’avez pas encore.
Il faut installer ces bibliothèques pour pouvoir utiliser HuggingFace
!pip install huggingface_hub
!pip install -q datasets seqeval
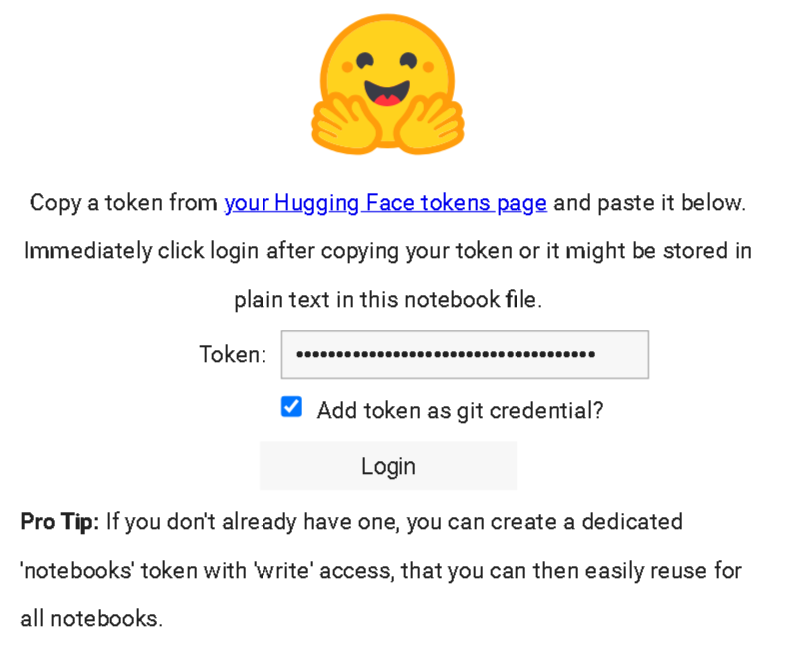
Pour pouvoir hoster votre data sur HuggingFace, vous devez avoir une token key. Cela se trouve dans votre compte HuggingFace.
from huggingface_hub import notebook_login
# hf_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX , this the token to put , Get Yours
notebook_login()
7.1.3 Création de le DataSet
from sklearn.model_selection import train_test_split
from datasets import Dataset, Features, Sequence, ClassLabel, Value, Image
dataset_features = Features({
'id': Value('string'),
'image': Image(decode=True),
'bboxes': Sequence(Sequence(Value('int64'))),
'ner_tags': Sequence(ClassLabel(names=['InvNum','InvDate', 'Fourni' ,'TTC','TVA','TT' ,'Autre'])),
'tokens': Sequence(Value('string')),
})
Les colonnes de dataset sont définies ici : id, images, box,ner_tags,tokens avec le type de données de chacune.
Note
Pour names de ner_tags colonne , il faut remplacer avec vos propres classes en respectant l’ordre.
c-à-d l’ordre avec le quelle on a encodé les classes, par exemple si on désigne 0 pour InvNum , il faut le mettre le premier dans names.
Le type Sequence comme une liste en python.
# Convert the final_dataset into a dictionary of lists
data_dict = {
'id': [item['id'] for item in dataSet],
'image': [item['image'] for item in dataSet],
'bboxes': [item['bboxes'] for item in dataSet],
'ner_tags': [item['ner_tags'] for item in dataSet],
'tokens': [item['tokens'] for item in dataSet],
}
# Convert the dictionary of lists into a HuggingFace Dataset
hf_dataset = Dataset.from_dict(data_dict, features=dataset_features)
ds = hf_dataset.train_test_split(test_size=0.07,shuffle=True,seed =10)
Ici on split le dataset en 2 parties : 93% pour l’entrainement et 7% pour le test, vous pouvez choisir un autre pourcentage.
ds.push_to_hub("ID_YOUR_DATASET_NAME")
On push aprés le dataSet a notre compte HuggingFace. ID_YOUR_DATASET_NAME est par exemple Textra/Textra_Data

Indication
le DataSet sur HuggingFace pour Exemple des deux images ici.
Vous trouvez tout le code en colab.
7.2 Entrainement
Vous pouvez entrainer sur Colab,Kaggle ou un notre service Cloud, ou sur votre propre machine si elle satisfait des conditions de capacité dont on parle ultérieurement.
Indication
pour notre cas on entrainera sur Google Colab.
Il faut savoir qu’une fois vous fermez l’onglet de colab, la prochaine fois il faut réinstaller toutes les bibliothèques utilisé, car vous connectez à une nouvelle machine.
Il faut utiliser la machine T4 de colab, car on besoin d’un GPU pour accélérer l’entraînement.
!pip install -qqq transformers[torch] accelerate==0.20.1
!pip install -q datasets seqeval
!pip install huggingface_hub
from huggingface_hub import notebook_login
# hf_XXXXXXXXXXXXXXXXXXXXXXXXXXX , this the token to put , Get Yours
notebook_login()
Ici, on installe quelques bibliothèques qu’on aura besoin pour l’entraînement. Ainsi, on fait un LogIn avec le même token que vous avez déjà obtenu sur HuggingFace.
from datasets import load_dataset
ds = load_dataset("ID_YOUR_DATASET_NAME")
obtenir votre dataset pour l’entrainement. dans le notebook de trainning vous trouvez quelques linges afin de découvrir la variable ds.
7.2.1 Prétraitement des données
Vous pouvez consulter la documentation du modèle LayoutLM sur HuggingFace . On va utiliser le modèle de base de LayoutLMv3 (Il y a base,Large..).
from transformers import AutoProcessor , LayoutLMv3Processor
processor = LayoutLMv3Processor.from_pretrained("microsoft/layoutlmv3-base", apply_ocr=False)
# We will use our own OCR (PAddle) not tyesseract
On crée l’objet processor pour le prétraitement des données. microsoft/layoutlmv3-base et ID de répertoire où se trouve le processeur pré-entraîné de Microsoft. aussi puisqu’on a utilisait Paddle-OCR on fait apply_ocr to False, car LayoutLMv3Processor utilise par défaut tyesseract_OCR.
from datasets.features import ClassLabel
features = ds['train'].features
column_names =ds["train"].column_names
image_column_name = "image"
text_column_name = "tokens"
boxes_column_name = "bboxes"
label_column_name = "ner_tags"
# In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
# unique labels.
def get_label_list(labels):
unique_labels = set()
for label in labels:
unique_labels = unique_labels | set(label)
label_list = list(unique_labels)
label_list.sort()
return label_list
if isinstance(features[label_column_name].feature, ClassLabel):
label_list = features[label_column_name].feature.names
# No need to convert the labels since they are already ints.
id2label = {k: v for k,v in enumerate(label_list)}
label2id = {v: k for k,v in enumerate(label_list)}
else:
label_list = get_label_list(dataset["train"][label_column_name])
id2label = {k: v for k,v in enumerate(label_list)}
label2id = {v: k for k,v in enumerate(label_list)}
pour cette partie on crée deux listes id2label et label2id qu’on aura besoin aprés.
def prepare_examples(examples):
images = examples[image_column_name]
words = examples[text_column_name]
boxes = examples[boxes_column_name]
word_labels = examples[label_column_name]
encoding = processor(images, words, boxes=boxes, word_labels=word_labels,
truncation=True, padding="max_length",max_length= 512)
return encoding
from datasets import Features, Sequence,Value, Array2D, Array3D
features = Features({
'pixel_values': Array3D(dtype="float32", shape=(3, 224, 224)),
'input_ids': Sequence(feature=Value(dtype='int64')),
'attention_mask': Sequence(Value(dtype='int64')),
'bbox': Array2D(dtype="int64", shape=(512, 4)),
'labels': Sequence(feature=Value(dtype='int64')),
})
train_dataset = ds['train'].map(
prepare_examples,
batched=True,
remove_columns=column_names,
features=features,
)
eval_dataset = ds['test'].map(
prepare_examples,
batched=True,
remove_columns=column_names,
features=features,
)
On va mapper ds[“train”] et ds[“test”] avec la fonction prepare_examples afin d’avoir une format propice pour LayoutLMv3.
7.2.2 Charger le modèle
from transformers import LayoutLMv3ForTokenClassification
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = LayoutLMv3ForTokenClassification.from_pretrained("microsoft/layoutlmv3-base",
id2label=id2label,
label2id=label2id).to(device)
Vous pouvez rencontrer un Warning lors d’execusion de cette cellule, ne pas prendre en compte.
from transformers import TrainingArguments, Trainer
from huggingface_hub import HfFolder
hf_repository_id = "ID_YOUR_MODEL" # The ID of the Model Repo I created in Hugging to Host the model files and parametres
training_args = TrainingArguments(output_dir=hf_repository_id,
max_steps=1000,
per_device_train_batch_size=6,
per_device_eval_batch_size=5,
learning_rate=1e-6,
lr_scheduler_type = "cosine",
evaluation_strategy="steps",
eval_steps=100,
load_best_model_at_end=True,
metric_for_best_model="f1",
# This parameters are optional if we want to push results to huggingface
push_to_hub=True,
hub_strategy="every_save",
hub_model_id=hf_repository_id,
hub_token=HfFolder.get_token()
)
ID_YOUR_MODEL un nom que vous allez donner à votre modèle, par exemple Textra_Model. Un répertoire pour le modèle va être créé automatiquement dans votre espace sur HuggingFace.
Attention
Une étape importante dans ce processus est la définition des hyperparamétres de votre modèle, et ça dépend de votre data et architecture de modèle utilisé.
Une description complète sur ces hyperparamètres ici ,on vous recommande de la consulter.
Si vous exécuter la cellule plus q” une fois sans changer hf_repository_id, vous écrasez à chaque fois le modèle déjà existent.
Remarque : pour le Learning rate, modifiez la valeur de celui-ci à chaque fois et voir les résultats , on a trouvé les meilleurs valeurs ( 1e-5 , 5e-5 , 6e-6 , 7e-6 ), la batch size affectera considérablement le training c’est comme une régularisation pour éviter Overfiting.
Si vous avez un problème avec la Validation loss **, qui augmante par exemple peut être que le **lerning rate est grand essayer de le réduire un petit peu.
Si vous voulez augmenter la batch size , en général, vous devez avoir un (Pour le LayoutlmV3-Large)
GPU >= 20 Go vers train_batch_size = 3
GPU >= 24 Go à train_batch_size = 4.
Indication
Pour vous aider, on vous recommande aussi de tester différentes valeurs de ces paramètres :
gradient_accumulation_steps = 4,5,…
weight_decay = 0.09 (entre 0 and 0.1 c’est aussi pour la régularisation)
lr_scheduler_type = « linear », »cosine », »constant »…
warmup_steps = 100,200… (ne dépasser pas max_steps)
per_device_train_batch_size : c’est la taille de chaque batch dans le training.
from transformers.data.data_collator import default_data_collator
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=processor,
data_collator=default_data_collator,
compute_metrics=compute_metrics,
)
torch.cuda.empty_cache()
trainer.train()
On crée l’objet trainer, et on vide les donnés cachés dans le GPU, aprés on lance l’entrainement.
# Save processor and create model card
processor.save_pretrained(hf_repository_id)
trainer.create_model_card()
trainer.push_to_hub()
Sauvgarder model_card,les fichiers du modèle ansi historique de training avec push_to_hub.