OCR
3.1 C’est quoi OCR ?
OCR signifie Reconnaissance Optique de Caractères. C’est la technologie qui permet aux logiciels de reconnaître du texte dans des images ou des documents numérisés, et de le convertir en données modifiables et recherchables
3.3 OCR Bechmarking
3.3.1 EasyOCR
est un logiciel de reconnaissance optique de caractères (OCR) open-source développé en Python. Il permet de convertir des images ou des fichiers PDF contenant du texte en texte éditable et recherchable. EasyOCR est conçu pour être facile à utiliser et offre une bonne précision de reconnaissance pour plusieurs langues, y compris des langues asiatiques comme le chinois, le japonais et le coréen. Il prend en charge plusieurs plates-formes, notamment Windows, macOS et Linux, et peut être intégré dans des applications grâce à une interface simple et des fonctionnalités avancées telles que la détection de langage automatique, la segmentation de texte et la reconnaissance de mise en page.
import pandas as pd
import matplotlib.pyplot as plt
import cv2
from PIL import Image, ImageDraw, ImageFont
import numpy as np
def Plot_EsyOCR(image_path, results, Threshold,Time,text_size=20):
img = cv2.imread(image_path)
font = cv2.FONT_HERSHEY_SIMPLEX
for detection in results:
if detection[2] >= Threshold:
bbox = detection[0]
text = detection[1]
conf = detection[2]
x1, y1 = bbox[0]
x2, y2 = bbox[1]
#cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 150), 2)
cv2.putText(img, f"{text}", (int(x1), int(y1) - 10), font,0.7, (0, 0, 255), 2)
cv2.putText(img, f"{conf:.2f}", (int(x1), int(y1)-30), font, 0.7, (255, 0, 0), 2)
# Display the image using matplotlib
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(16, 16))
plt.imshow(img_rgb)
plt.axis('off')
plt.title(f"EasyOCR : {Time} seconds")
plt.show()
start_time = time.time()
results = reader.readtext(Image_path)
end_time = time.time()
Time = end_time - start_time
Plot_EsyOCR(Image_path,results,0.9,round(Time))
#df = pd.DataFrame(results,columns=['bbox','text','conf'])

3.3.2 Paddle_OCR
est un outil OCR (Reconnaissance Optique de Caractères) open-source développé par PaddlePaddle,un framework d’apprentissage profond développé par Baidu. PaddleOCR est conçu pour reconnaître du texte à partir d’images et de documents en utilisant des techniques d’apprentissage profond. Il prend en charge différentes langues et fournit des modèles pré-entraînés pour différentes tâchestelles que la détection de texte de scène, la reconnaissance et le repérage de texte. PaddleOCR est reconnu pour sa précision, son efficacité et sa facilité d’utilisation, ce qui en fait un choix populaire pour les développeurs et les chercheurs travaillant sur des projets liés à l’OCR. Il offre à la foisdes outils en ligne de commande et des APIs Python pour une intégration dans diverses applications.
Installation:
!pip install "paddleocr>=2.0.1" # Recommend to use version 2.0.1+
Les bibliothèques
import time
import cv2
import numpy as np
import matplotlib.pyplot as plt
Fonction Plot Paddle
def Plot_Paddle(results,Image_path,Time,Threshold):
image = cv2.imread(Image_path)
# Annotate the image with recognized text and confidence
for result in results:
for box, text_info in result:
# Extract text and confidence
text, confidence = text_info
if confidence >= Threshold:
# Convert coordinates to numpy array of integers
box = np.array(box, dtype=np.int32)
box = box.reshape((-1, 1, 2))
# Draw bounding box
cv2.polylines(image, [box], isClosed=True, color=(0, 255, 0), thickness=2)
# Add text with confidence
cv2.putText(image, f"{text} ", (box[0][0][0], box[0][0][1] - 5),cv2.FONT_HERSHEY_SIMPLEX,0.5, (0, 0, 255), 1)
cv2.putText(image, f"{confidence:.2f} ", (box[0][0][0], box[0][0][1] - 20),cv2.FONT_HERSHEY_SIMPLEX,0.5, (255, 0, 0), 1)
# Convert BGR to RGB
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Plot the annotated image using Matplotlib
plt.figure(figsize=(16, 16))
plt.imshow(image_rgb)
plt.axis('off')
plt.title(f"Paddle_OCR : {Time} seconds")
plt.show()
def Run_Paddle(Image_path):
ocr = PaddleOCR(use_angle_cls=True, lang='fr') # need to run only once to download and load model into memory
start_time = time.time()
results = ocr.ocr(Image_path, cls=True)
end_time = time.time()
Time = end_time - start_time
return results,Time
results,Time = Run_Paddle(Image_path)
Plot_Paddle(results,Image_path,round(Time),0.9)
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='fr')
# Replace 'path_to_your_image.jpg' with the path to your image file
image_path = Image_path
# Perform OCR on the image
result = ocr.ocr(image_path, det=True, rec=True)
# Process the result
extracted_text = ''
for line in result:
for word in line:
# Access the text part of the tuple
extracted_text += word[1][0] + ' ' # Access the first element of the recognized text (the text itself)
extracted_text += '\n'
# Print the extracted text
print(extracted_text)
3.3.3 docTR
À propos de docTR (Document Text Recognition) - une bibliothèque fluide, performante et accessible pour les tâches liées à l’OCR, alimentée par l’apprentissage profond.
Installation:
!pip install python-doctr
!pip install "python-doctr[tf]"
!pip install "python-doctr[torch]"
!pip install tf2onnx
from doctr.io import DocumentFile
from doctr.models import ocr_predictor
import time
model = ocr_predictor(det_arch = 'db_resnet50', reco_arch = 'crnn_vgg16_bn',pretrained = True)
# Modify the binarization threshold and the box threshold
model.det_predictor.model.postprocessor.bin_thresh = 0.5
model.det_predictor.model.postprocessor.box_thresh = 0.2
img = DocumentFile.from_images('easy.jpg')
start_time = time.time()
result = model(img)
end_time = time.time()
Time = end_time - start_time
output = result.export()
print(Time)
result.show()
for obj1 in output['pages'][0]["blocks"]:
for obj2 in obj1["lines"]:
for obj3 in obj2["words"]:
print("{}: {}".format(obj3["geometry"],obj3["value"]))
Text = result.render()
print(Text)

3.4 Comparaison entre les outils d’OCR
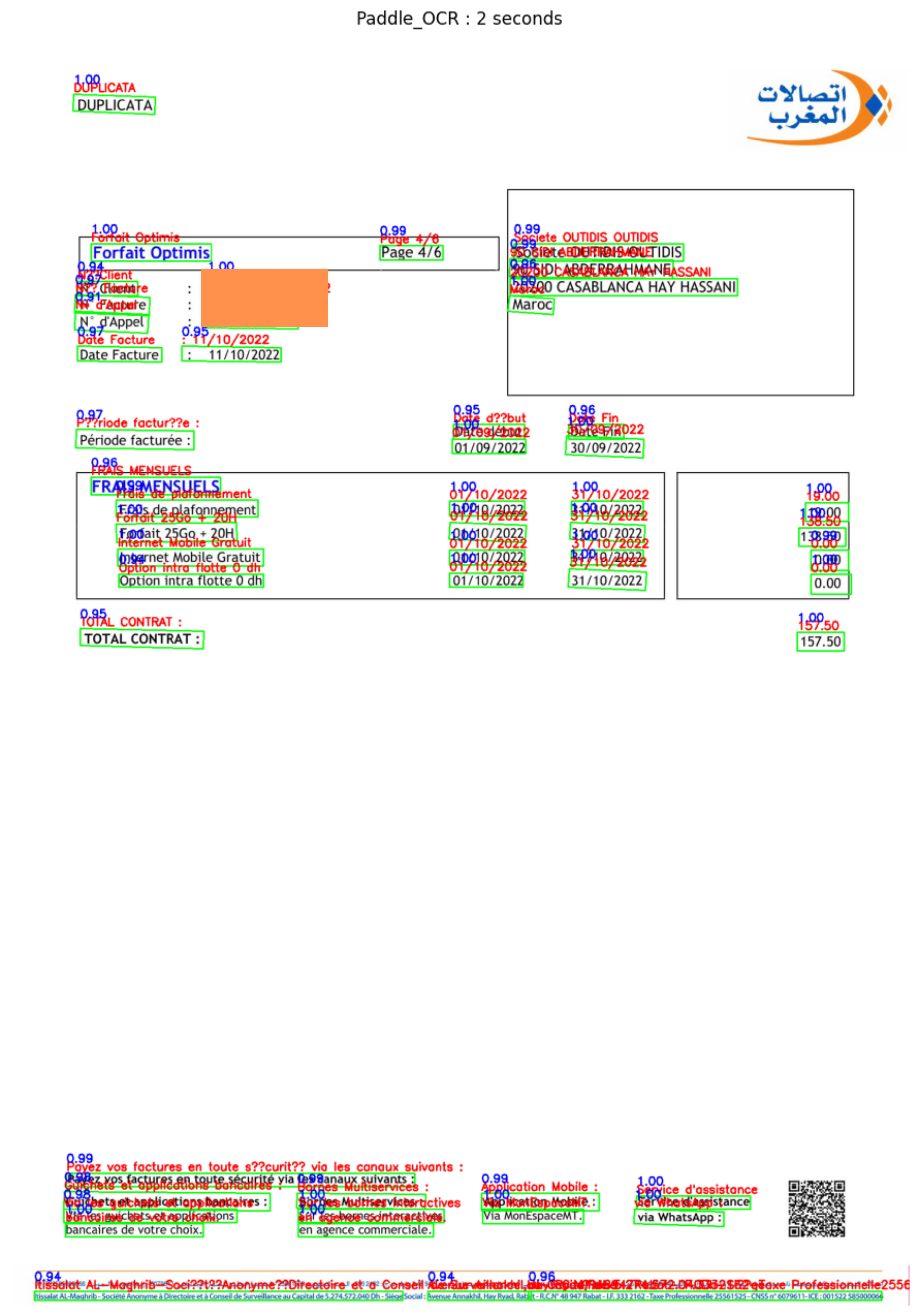
Nous avons traité deux images, une image simple (bien scanée et tout est clair) et l’autre image est un peu complexe (image pris par caméra de téléphone, défauts d’orientation ….). Vous trouvez ci-dessous les deux i mages qu’on a pris pour le test :
Pour EasyOCR :
Le temps de traitement de l’image : 49 secondes
La précision : ne détecte pas tous les champs des textes
Autres remarques : Incapable de lire les virgules (,) , les e accent (é è ) , A accent grave (à) , c cédille (ç) ….
Pour PaddleOCR :
Le temps de traitement de l’image : 2 secondes
La précision : détecte tous les champs des textes
Autres remarques : Incapable de lire les e accent (é è ), A accent grave (à) et les c cédille (ç) .
Pour docTR :
Le temps de traitement de l’image : 25 secondes
La précision : détecte tous les champs des textes
Autres remarques : Incapable de lire les e accent (é è ) , A accent grave (à) , c cédille (ç) ….
3.5 Choix de l’outil à utiliser
Après avoir tester plusieurs outils d’OCR ( easyOCR , PaddleOCR , Keras_OCR , Pytesseract , docTR).
Paddle_OCR est plus puissant au niveau de la précision, au niveau de la complexité de l’image et
aussi au niveau du temps d’exécution.
3.2 Comment ca fonctionne ?
La reconnaissance optique de caractères (OCR) implique plusieurs étapes pour convertir des images de texte en texte éditable:
Prétraitement de l’image: L’image est nettoyée pour améliorer la qualité et la lisibilité du texte. Cela peut inclure des opérations telles que la normalisation des couleurs, la suppression du bruit et l’amélioration du contraste.
Détection des régions d’intérêt: Les zones de l’image contenant du texte sont identifiées à l’aide de techniques de détection d’objets ou de segmentation d’image.
Reconnaissance des caractères: Les caractères individuels dans les régions d’intérêt sont identifiés à l’aide de modèles de reconnaissance de forme ou de réseaux de neurones convolutifs (CNN) pour reconnaître les formes des lettres et des chiffres.
Post-traitement: Une fois les caractères reconnus, des techniques de traitement du langage naturel peuvent être utilisées pour améliorer la précision de la reconnaissance en tenant compte du contexte et de la grammaire.